objdump
Linux反汇编命令
常用参数
objdump -d <file(s)>: 反汇编特定指令机器码的section;objdum -D <file(s)>:反汇编所有section
以上就是比对,可以看-D多了好多好多
objdump -S <file(s)>: 将代码段反汇编的同时,将反汇编代码与源代码交替显示(有时候就直接-DS)objdump -C <file(s)>: 将C++符号名逆向解析objdump -l <file(s)>: 反汇编代码中插入文件名和行号,和-d,-D一起使用时可以用-ld,编译时需要使用-g参数,即需要调试信息;objdump -j section <file(s)>: 仅反汇编指定的section;objdump -r section <file(s)>: 显示文件的重定位入口。如果和-d或者-D一起使用,重定位部分以反汇编后的格式显示出来
tmux使用
写着写着,感觉熟练掌握tmux确实是一个必要的手段,分窗格与窗口对效率提高还是不错的,其很多触发都与[C-b]相关
基本操作
- 新建会话
tmux new -s NameName为我们为新建会话取得名字 - [C-b]+c可以在会话里新建窗口
- 利用[C-b]+d将会话与进程分离,可以让会话先不受影响
- 可以利用
tmux a -t Name/Number回到原来的对话 - ``tmux ls`命令可以查看当前所有的 Tmux 会话
tmux switch -t Name/Number命令用于切换会话tmux kill -t Name/Number命令用于结束会话- 按住[C-b] + number 可以按照编号切换窗口
$ tmux rename-session -t 0 <new-name>用于重命名。
窗口-窗格操作
窗口选择
tmux new-window命令用来创建新窗口。(还有就是之前说的[C-b] + c)- [C-b] + p :上一个窗口(pre)
- [C-b] + n:切换到下一个窗口(next)
- [C-b] + ,: 重命名
- [C-b] + w: 列表选择窗口
划分窗格
也有命令,但感觉用命令太浪费了,还是记快捷键吧
- [C-b] % 左右划分
- [C-b] “: 划分上下
- [C-b]
: 光标切换到窗格(用方向键) - [C-b] : : 切换到上一个窗格
- [C-b] o: 切换到下一个窗格
- [C-b] {: 当前窗格与上一个交换位置
- [C-b] }: 与上一个改变位置
Ctrl+b Ctrl+o:所有窗格向前移动一个位置,第一个窗格变成最后一个窗格。Ctrl+b Alt+o:所有窗格向后移动一个位置,最后一个窗格变成第一个窗格。Ctrl+b x:关闭当前窗格。Ctrl+b !:将当前窗格拆分为一个独立窗口。Ctrl+b z:当前窗格全屏显示,再使用一次会变回原来大小。Ctrl+b Ctrl+<arrow key>:按箭头方向调整窗格大小。Ctrl+b q:显示窗格编号。
其他命令
下面是一些其他命令。
ELF文件
在编译过程中,汇编阶段(-c)会得到一个.o文件,链接(-o)会得到一个可执行文件。这些都算是目标文件,目标文件可以分为可重定位目标文件,可执行目标文件,和共享目标文件。
- 可重定位目标文件(.o):包含二进制代码和数据,其形式可以和其他目标文件进行合并,创建一个可执行目标文件
- 可执行目标文件(.out):包含二进制代码和数据,可直接被加载器加载执行
- 共享目标文件(.so):可被动态的加载和链接
组成结构
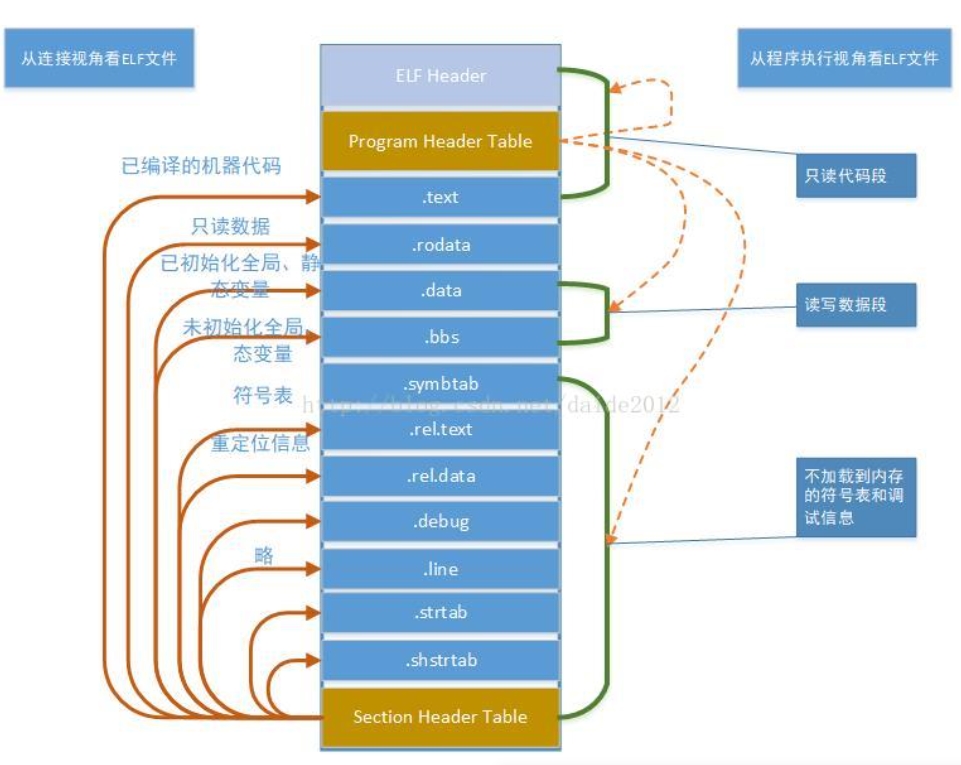
- ELF Header:包含程序到基本信息,包含了Section Header Table 和 Program Header Table相对文件的offset(就是指出他俩在什么位置)
- Program Header Table也可称作Segment Table,包含程序中 Segment到信息 (Segment到信息需要在运行时刻调用)
- Section Header Table, 包含Section信息,Section的信息用在编译和链接时刻
- Segments(段), Segment记录了每一段数据(包括代码等)需要被载入到哪里,其中记录的信息用于指导应用程序加载。
- Sections(节),Section记录了程序到代码段,数据段等各个段内容,在链接时使用。
Secgment可以认为是一些section的集合。OS加载程序时,不会逐个对节加载,而是对相同权限的节的集合做同样的操作。例如所有只读可执行的节(如代码节.text和初始化代码节.init)归并到一块等,这些大的section的集合就可以称为Segment
由上图可以看到Program Header Table 和 Section Header Table指向的是相同的位置,二者到内同是重合到。之所以可以这样的原因是两个模块发生作用并不同时。(空间的高效利用),Program Head Table用于组成可执行文件时,在运行时为加载器加载,而Section Header Table用于可重定向文件
MIPS内存布局
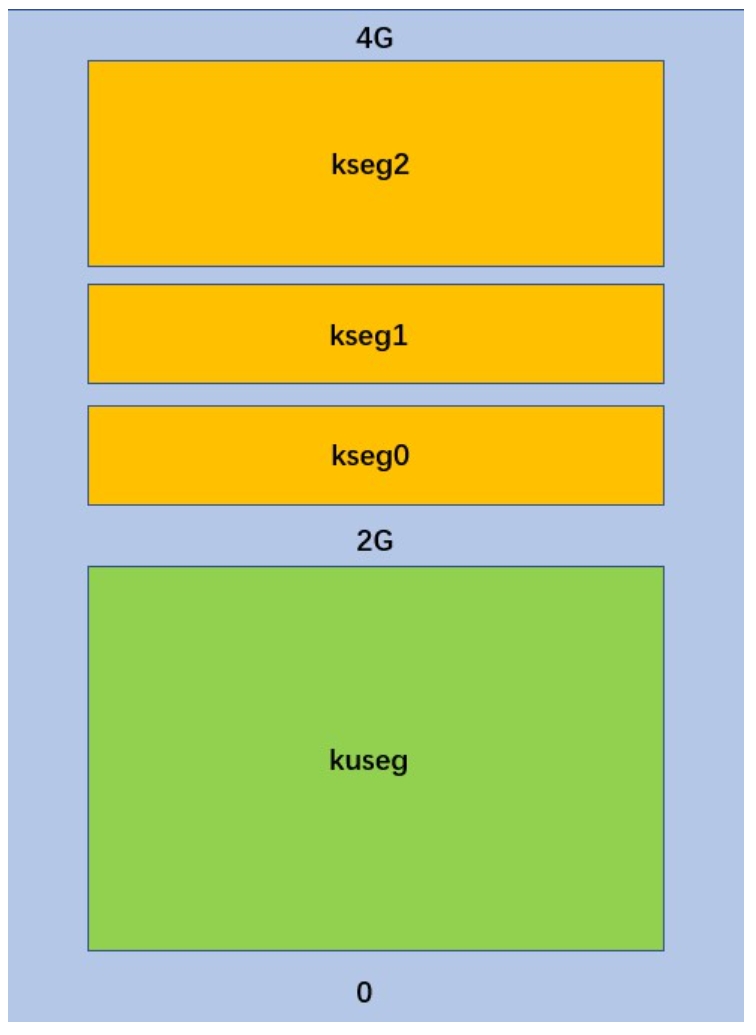
可以看到分为了四个区域,而kuseg很明显就是给用户态的,其余是是给核心态。从硬件角度
- User Space(kuseg): 为用户态可以用的地址,在使用这些地址的时候,程序会通过MMU(分页内存管理单元,就是一个地址翻译器,处理复杂的地址映射)映射到实际的物理地址上,空间地址为0x00000000-0x7FFFFFFF(2G)
- Kernel Space Unmapped Cache(kseg 0): 只需要将地址的高三位清零,地址就会被转换为物理地址(强制的规定好像),不需要MMU,称为无需转换的地址,一般情况下,通过cache对这段区间地址进行访问,地址区间在0x80000000-0x9FFFFFFF(512MB)
- Kernel Space Unmapped Uncached(kseg 1):这一段地址的转换规则与前者相似, 通过将高 3 位清零的方法将地址映射为相应的物理地址,重复映射到了低端 512MB 的物理地址。需要注意的是,kseg1 不通过cache 进行存取。地址区间是 0xA0000000-0xBFFFFFFF(512MB)
- Kernel Space Mapped Cacehd(kseg 2): 只能在kernel态使用,且需要MMU转换,地址空间为0xC0000000-0xFFFFFFFF(1GB)
而需要MMU进行映射访问而的地址,需要建立虚拟内存机制之后才能正常使用,而这个正是由操作系统所管理的。所以当我们需要bootloader加载内核时,显然操作系统还没有建立好,因此不能选择MMU的方法,就是要在kseg0 和 kseg1 选,而kseg1不经过cache,因此只能放在kseg0中。
可变长参数
当函数参数列表末尾有省略品,该函数即有变长的参数表。因为需要定位变长参数表的起始位置,函数需要至少一个固定参数,且变长参数必须在参数表的末尾。
这些都是stdarg.h所包含的类型和宏
va_list: 变长参数表的变量类型;va_start(va_list ap, lastrag), 用于初始化变长参数表的宏;va_arg(va_list ap, type), 用于取变长参数表下一个参数的宏;va_end(va_list ap), 结束使用变长参数表的宏。
在带变长参数表的函数内使用变长参数表,需要先声明一个类型为va_list的变量,然后用va_start进行初始化:
va_list ap;
va_start(ap, lastarg);
其中 lastarg 为该函数最后一个命名的形式参数。
在初始化后,每次可以使用 va_arg 宏按获取一个形式参数,该宏也会同时修改 ap 使得下次被调用将返回当前获取参数的 下一个参数。
例如
1
2
int num;
num = va_arg(ap, int);
var_arg的第二个参数为这次获取的参数的类型,如上述代码就从参数列表中取出 一个 int 型变量。 在所有参数处理完毕后,退出函数前,需要调用 va_end 宏一次以结束变长参数表 的使用。
在所有参数处理完毕后,退出函数前,需要调用 va_end 宏一次以结束变长参数表的使用。